投稿日:2025年2月14日 | 最終更新日:2026年1月8日
SEO対策を行う上で重要なのが「クローラー」。これは「ロボット」「ボット」「スパイダー」とも呼ばれる検索エンジンの巡回プログラムです。
Googleなどの検索エンジンで自社サイトを表示させるためには、このクローラーに認識してもらう必要があります。今回は、SEOを学びたい初心者向けに、クローラーとは何か、検索エンジンでの役割、そしてクローラーに適したサイト作りについて解説します。
クローラー(Crawler)とは?

クローラーは、検索エンジンの巡回プログラムです。英語の「crawl(這いまわる)」が語源で、クローラーは自動的にWebサイトを巡回し、情報を収集します。このクローリングにより、検索エンジンのデータベースが作成され、検索結果が生成されます。
検索エンジンの仕組み

クローラーが集めた情報は、次のステップを経て検索エンジンに反映されます。
- クローラーが収集したデータをインデックス化
- インデックス化されたページをランク付け
- ランク付けされた結果を検索結果として表示
クローラーが収集した情報をもとに、検索エンジンは独自のアルゴリズムで各ページをランク付けし、それが検索結果の順位に「反映」されます。
クローラーの役割

クローラーの役割は、検索エンジンのための情報収集。インターネット上をクローリングし、必要な情報を収集・解析・登録していきます。それでは、クローラーの種類やインターネット上で何をチェックしているのかを解説していきましょう。
クローラーとSEOの関係について
SEOとは、検索エンジンで自社サイトを上位に表示させるための施策のことです。クローラーが正しく自社サイトの情報を収集しなければ、どれだけSEO対策を行っても検索結果に表示されません。そのため、クローラーが効率よくサイトを巡回できるように、サイトの構造や施策が重要です。
クローラーの種類について
クローラーは、検索エンジンごとに異なるプログラムが使用されています。たとえば、Googleのクローラー「Googlebot」や、Bingの「Bingbot」などです。これらのクローラーが、世界中のインターネット空間を巡回して情報を集めています。
日本で最大のシェアを誇る検索エンジンはgoogleであるため、そのクローラーである「Googlebot」を意識したクローラー対策に注力することになります。
Googlebotは、Googleの検索エンジンが使用するクローラーです。主な種類は以下の通りです。
- Googlebot(デスクトップ用): 一般的なパソコン向けのWebページをクロールします。
- Googlebot-Image(画像用): 画像ファイルを主にクロールします。
- Googlebot-Mobile(モバイル用): スマートフォンやタブレット向けのWebページをクロールします。
但し、2023年10月末に、Googleはモバイルファーストインデックスへの移行を完了したと発表しました。
2024年7月5日以降は、すべてのサイトのクロールがスマートフォン用Googlebotで実行されるようになります。パソコン用Googlebotによるクロールは基本的に終了しています。
その他のクローラーは検索エンジンごとに異なり、下記のように様々な種類のものがあります。
- Yahoo!:Yahoo! Slurp
- Baidu(中国大手の百度):Baiduspider
- Bing(マイクロソフト社):Bingbot
- Naver(韓国大手): NaverBot
クローラーの対象ファイル
クローラーがチェックする情報は、インターネット上のファイルです。人間が閲覧できる情報(文書・画像・動画ファイル)をクローリングしています。具体的には下記のファイル形式が挙げられます。
- HTML
- CSS
- 画像
- 動画
- Java ScriptFlash
- テキスト
- 地理データ
- 音声
クローラビリティの向上
クローラビリティとは、クローラーがサイトを巡回しやすい状態を指します。特に、大規模なサイトではクローラビリティを意識することが重要です。新しいページが速やかにクローラーに認識されるよう、サイトの構造や内部リンクの最適化、ページ表示速度の改善などを行いましょう。
モバイル対応の重要性
Googleは、モバイルファーストインデックスへの完全移行を完了し、現在ではすべてのサイトがスマートフォン向けのGooglebotでクロールされています。これにより、モバイル対応がSEO対策においてますます重要となっています。モバイルフレンドリーなデザインや、モバイル端末での表示速度の最適化は、クローラーによる評価に直接影響を与えるため、モバイル対応の重要性を再確認し、サイト全体の見直しを行うことが求められます。
クロール最適化のポイントを解説

SEO対策と同様、クロール最適化も一度行えば終わりではありません。新しいページの追加や既存ページの修正時には、クローラーがすぐにそれを認識できるように、Google Search Consoleを活用し、定期的にクロールリクエストや内部リンクの見直しを行う必要があります。
いくらSEOを徹底しても、クローラーにサイト情報を正しくピックアップしてもらわなければ、検索結果に表示されません。また、クローラーに十分評価されなければ、狙ったキーワードで正しく検索してもらうこともできません。
まずは、クローラーに自社サイトの更新情報や新しいページを、速く正確にキャッチしてもらうことが重要です。そのために必要なのがクローリングの「最適化」です。ここからは、クローリングの最適化について解説します。
WordPressを利用してオウンドメディアを運用している企業様も多いと思います。各関連した項目で対応のプラグイン「All in One SEO」:略してAIOSEOの解説を致します。
初心者でも導入が簡単でコーディングの知識など不要で調整できるためです。
URL:https://ja.wordpress.org/plugins/all-in-one-seo-pack/
クローラビリティを意識する
IT業界でウェブサイトの使いやすさを「アクセシビリティ」と呼ぶように、クローラーがサイトを巡回しやすくする工夫を「クローラビリティ」と呼びます。
小規模サイトではそれほど意識する必要はありませんが、1000ページ以上の大規模サイトの場合はクローラビリティは必須。クローラーが効率良く巡回できるサイトを構造にしなければ、新しく作成したページが検索されないこともあります。
クローラビリティのために有効な手段は以下です。
- 重要なコンテンツは上位階層に(トップページから2クリックでアクセスできるように)
- 画像ではなくテキストリンクを設置する
- ページ表示速度を改善(速く表示されるように)
- Javascriptを最適化
- 同じジャンルの情報をまとめ、1つのディレクトリにまとめる
クロールリクエストの実施
手っ取り早いクローリングの方法は、検索エンジン側にクローリングをリクエストすることです。Googleの場合は、このリクエストが可能です。
リクエストにはGoogle提供の無料ツール「Google Search Console」を使います。「Google Search Console」の機能の1つである「URL検査」で、Googleにリクエストをかけましょう。
リクエストは、新しいサイトを作った、新しいページを公開したなど、早めにクローラーにキャッチしてほしい情報がある場合に有効です。
構造化データの重要性
構造化データの活用は、SEOの分野でますます重要性を増しています。構造化データを正しく導入することで、検索エンジンがWebサイトの内容をより正確に理解できるようになり、リッチスニペットなどの表示にもつながります。
Schema(スキーマ)とは、Webページの情報を検索エンジンに対してより分かりやすく伝えるための構造化データのことです。スキーマは、検索エンジンがWebページの内容を理解しやすくするために、特定のフォーマットで情報を整理する役割を果たします
以下、スキーマと省略させていただきます。
例えば、Schema.orgのマークアップを使用して、ページの情報を検索エンジンに明示することができます。これにより、クローラーがサイトをクロールする際に、より効率的に情報を収集・理解し、SEO効果を高めることが可能です。
他には、Google Search Central のリッチリザルトテストをお役立てください。
・Google Search Central
URL: https://developers.google.com/search/docs/appearance/structured-data?hl=ja
・リッチリザルトテスト
URL: https://search.google.com/test/rich-results?hl=ja
All in One SEOでの構造化データの設定方法
All in One SEOのスキーマ設定を使えば、ページごとに簡単に構造化データを設定することができます。まずは無料版で十分です。無料版では、基本的なArticleスキーマが自動的に追加されるため、特にブログ記事やニュース記事を扱う場合には、それだけでSEO効果を得ることが可能です。
無料版の理由としては、無料版では基本的なArticleスキーマが利用でき、これが多くのサイトで必要とされる主要なスキーマであるためです。
ただし、より高度な構造化データが必要な場合や、製品ページやイベントなど特定のタイプのスキーマを追加したい場合は、Pro版へのアップグレードを検討するのが良いでしょう。
注目するべきポイントとしては記事を更新している2024年10月18日現在では、無料版でも利用できるスキーマが増えている点です。
All in One SEO (AIOSEO) の最新バージョンでは、無料版でも以前より多くのスキーマタイプが利用可能になっています。具体的には:
- Article スキーマ
- WebPage スキーマ
- Organization スキーマ
- Person スキーマ
- FAQ スキーマ
- Local Business スキーマ (基本的な情報のみ)
これらのスキーマタイプは、以前は有料版でのみ利用可能だったものの一部です。無料版でこれらが利用可能になったことで、基本的なSEO最適化の幅が広がりました。
つまり、Wordpressサイトの簡単な構造化データの対応はこちらのプラグインを入れておけば最低限は対応できるということです。
All in One SEOのPro版で利用できる機能
- 様々なスキーマタイプ(製品、レシピ、FAQ、イベントなど)の追加
- カスタムスキーマの作成
- ローカルビジネススキーマ
- 動画SEOスキーマ
- WooCommerceの製品スキーマ
Pro版では、スキーマジェネレーターを使用して、コーディングの知識がなくても簡単に構造化データを追加することができ、またGoogleナレッジグラフのサポートも含まれています。
そのため、高度な構造化データ機能をフルに活用して、検索エンジンにより正確な情報を伝えたい場合は、Pro版へのアップグレードがおすすめです。
しかし、基本的な記事中心のオウンドメディアでArticleスキーマで十分な場合は、無料版でも効果的に活用できます。
サイトの規模や目的に応じて、無料版かPro版を選ぶことが、最適なSEO対策への第一歩となるでしょう。
XMLサイトマップの作成&送信
XMLサイトマップは、Webサイトの構造をXML形式で記述したファイルです。検索エンジンに、Webサイトのページのリストとその間の関係を伝えることで、クローラーがWebサイトを効率的にクロールできるようにします。XMLサイトマップには、ページのURL、最終更新日時、変更頻度、優先度などの情報を含めることができます。
簡単に説明しますとXMLサイトマップとは、自社サイトの設計図のようなものです。このサイトマップをサーバに設置しておきます。これによって、クローラーが手早くサイト構成を理解し、効率よく情報を収集してもらいやすくなります。
XMLサイトマップは、前述のGoogle無料ツール「Google Search Console」の「サイトマップ」から送信できます。
All in One SEOでのXMLサイトマップの作成と送信方法
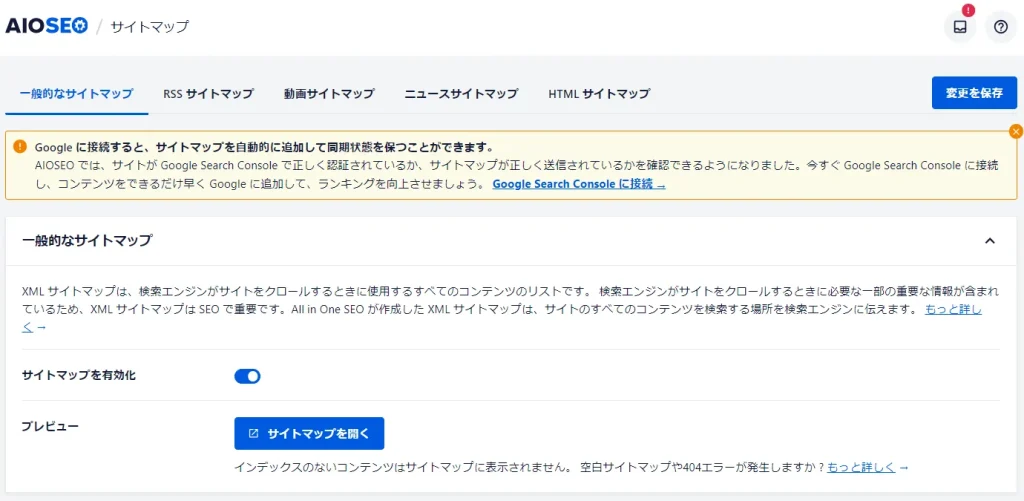
All in One SEOにはXMLサイトマップ作成機能が内蔵されており、特別な技術や知識がなくても簡単にサイトマップを作成・送信することができます。まずは無料版から始めることができます。デフォルトでは、この機能が自動的に有効化されているため、基本的な操作だけでサイトマップを作成できます。単純にインストールして初期設定を行えば良いということです。
具体的な手順:
- All in One SEOをインストールし、有効化すると、デフォルトでXMLサイトマップ機能がオンになっています。
- 管理画面の「All in One SEO」→「サイトマップ」から設定画面にアクセスし、「一般的なサイトマップ」のタブで、XMLサイトマップが有効になっていることを確認しましょう。
- デフォルトでは、投稿、固定ページ、カテゴリーなど、主要なコンテンツタイプがサイトマップに含まれるように設定されています。
- サイトマップは自動的に生成され、通常は「https://あなたのサイト.com/sitemap.xml」のURLでアクセスできます。
自動更新とGoogle Search Consoleでの送信:
- サイトマップは、新しいコンテンツが追加されたり、既存のページが更新されたりすると自動的に更新されます。
- ただし、Google Search Consoleに手動でサイトマップを送信することで、より確実にGoogleに認識させることができます。このプロセスにより、クローラーがより効率的にサイト全体を巡回することが可能になります。
All in One SEOを使えば、特別な設定をしなくてもXMLサイトマップは自動生成されますが、さらに細かく最適化したい場合は、サイトマップ設定画面で調整可能です。例えば、特定のページをサイトマップから除外したり、更新頻度や優先度をカスタマイズすることができます。
有料版(Pro版)のメリット: 無料版でも基本的なサイトマップ機能は十分利用できますが、Pro版ではより詳細なカスタマイズが可能です。例えば、特定のコンテンツを除外したり、動画やローカルビジネスに対応したサイトマップを作成するなど、より高度な最適化が簡単に行えます。
robots.txtの設置
robots.txtは、Webサイトのルートディレクトリに配置するテキストファイルで、検索エンジンのクローラーに対して、どのページをクロールして、どのページをクロールしてほしくないかを指示することができます。例えば、特定のディレクトリやファイルのクロールを禁止したり、特定のユーザーエージェント(クローラーの種類)に対してのみアクセスを許可したりすることができます。
robots.txtはクローラーの動きを制御するためのものです。まだ制作中のサイトや内容が薄いページは、クローラーが低評価をしがちです。サイトの中には、「クローラーに情報収集してほしくない」というページもあることでしょう。robots.txt(ロボットテキスト)の設置はそのための対策です。
robots.txtには、巡回してほしいページのURLを記載します。一番上のディレクトリに設置することで、クローラーに指示・制御が可能です。
All in One SEOでのrobots.txtファイルの設定方法
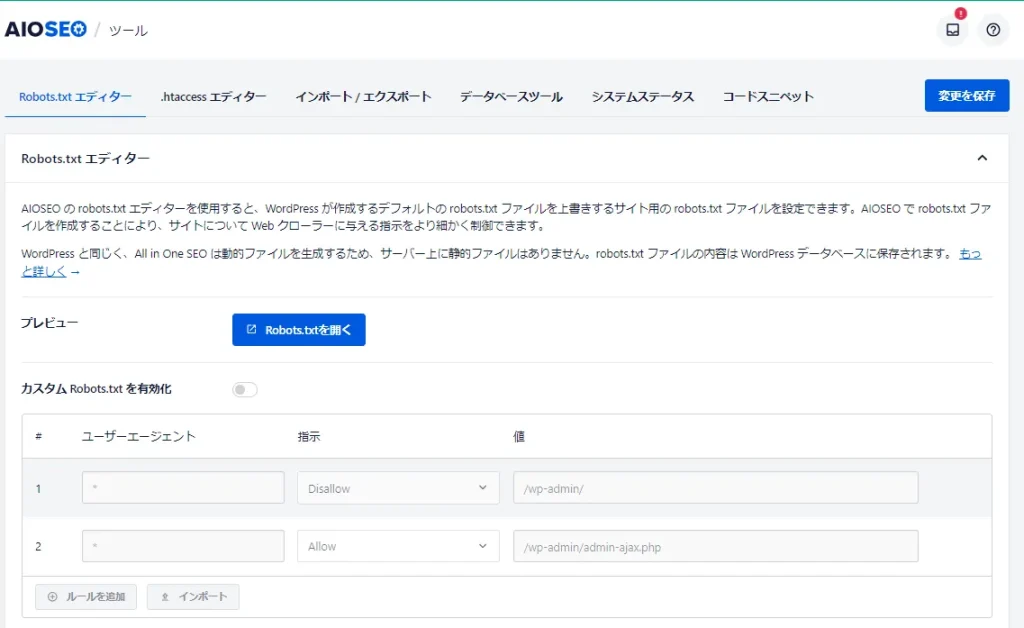
All in One SEOでは、robots.txtファイルを簡単に編集・管理することができ、手動でファイルを作成してアップロードする必要がありません。このプラグインを使用すれば、WordPressの管理画面から直接robots.txtファイルを作成・編集し、検索エンジンのクローラーが巡回する範囲を簡単に調整できます。
具体的な設定方法:
- WordPressの管理画面で「All in One SEO」→「ツール」を選択します。
- 「Robots.txtエディター」セクションを見つけ、「カスタムRobots.txtを有効化」のトグルをオンにします。
- 画面下部の「Robots.txtプレビュー」セクションで、現在のrobots.txtの内容を確認できます。
- ルールを追加するには:
- 「ユーザーエージェント」フィールドにユーザーエージェントを入力します(*を使用すると、全てのユーザーエージェントに適用されます)。
- 「許可する」または「許可しない」を選択し、クローラーのアクセスを制御します。
- 「ディレクトリパス」フィールドに対象のパスを入力します。
- 「ルールを作成」ボタンをクリックし、必要に応じて複数のルールを追加します。
- 変更を保存すると、All in One SEOが自動的にrobots.txtファイルを生成し、適切な場所に配置します。
このように、All in One SEOを使えば、手動でファイルを作成・アップロードする手間が省けるだけでなく、管理画面から直接編集が可能になります。また、プラグインが自動的にファイルを適切な場所に配置するため、配置場所を心配する必要もありません。
All in One SEOは、SEOの専門知識がない方でも簡単にrobots.txtを設定できるようサポートしてくれます。これにより、クローラーにアクセスを許可するページや除外するページを効果的に管理できるため、SEO対策にも役立ちます。こちらの機能を使う必要性がなければ、この機能を利用しなくても大丈夫です。
All in One SEOはサービス名と同様に本当にオールインワンで対応できてしまうのでWordpressでサイト運用されている企業さまは導入することをおすすめします。
内部リンクの最適化
内部リンクとは文字通り、同じサイト内のリンクです。関連するコンテンツをリンクで紹介することで内容を深め、クローラーも巡回しやすくなります。
内部リンクはサイト内の全てのページに設置しましょう。記事メディアのポイントは、関連記事の内部リンクです。内部リンクでサイト内を網羅するためにも、関連記事を増やしましょう。
本記事のこちらの項目が該当する箇所となります。

URLの見直し
URLの最適化は、SEOの基本的な要素の一つです。以前は、「www.」の有無による重複ページが問題視されていましたが、現在はこのような技術的な問題は減少しています。それでも、URLの重複や正規URLの設定は引き続き重要なポイントです。特に、同じページが複数の異なるURLでアクセスできる場合、Googleの評価が分散され、検索順位に悪影響を及ぼす可能性があります。
All in One SEO (AIOSEO)でのcanonicalタグの自動生成
AIOSEOを使用すると、canonicalタグが自動的に各ページに追加され、URLの重複によるSEO上の問題を防ぐことができます。以下に詳細を解説します:
デフォルト設定: AIOSEOはデフォルトでcanonicalタグを自動生成し、各ページに追加します。このため、特別な設定を行わなくても、適切なURLが検索エンジンに認識されるようになります。
自動生成機能: プラグインはWordPressの構造を理解し、各ページに対して正規のURLを自動的に判断してcanonicalタグを生成します。これにより、URLの重複を回避し、SEOの最適化がスムーズに行われます。
カスタマイズ可能: 必要に応じて、個々のページや投稿ごとにcanonical URLをカスタマイズすることも可能です。この設定は、AIOSEOのページ編集画面の「Advanced」タブで簡単に行えます。
確認方法: 設定が正しく機能しているか確認するには、ページのソースコードを表示し、<head>セクション内にcanonicalタグが存在しているかをチェックしてください。
特定ページの制御: 特定のページでcanonicalタグを削除したい場合は、PHPのフィルターフックを使用して制御することが可能です。
注意点: 以前のバージョン(All in One SEO Pack)では、canonicalタグを有効にするために手動でチェックを入れる必要がありましたが、現在のAIOSEOではデフォルトで有効になっており、特別な設定は不要です。
パンくずリストの調整
パンくずリストとは、サイトの上部に設置されているナビゲーションリンクのことで、ユーザーが自分がサイト内のどの位置にいるかを把握するための手助けをします。これにより、ユーザーが迷うことなくサイト内を移動できるだけでなく、クローラーにとってもサイト構造を理解しやすくなるため、サイト内の回遊を促す重要な要素です。
All in One SEO (AIOSEO) のパンくずリスト機能
AIOSEOプラグインを利用すると、パンくずリストに関するいくつかの便利な機能が利用できますが、無料版と有料版(Pro版)で機能に違いがあります。
- 無料版:
- AIOSEOの無料版では、パンくずリストに関連する構造化データを自動生成します。これにより、Googleの検索結果において、パンくずリストが表示される可能性が高まります。
- ただし、サイト上に実際にパンくずリストを表示する機能は含まれていません。サイト上で視覚的にパンくずリストを表示したい場合は、テーマの機能を利用するか、カスタムコードを追加する必要があります。
- 有料版 (Pro):
- 有料版では、構造化データの自動生成に加えて、サイト上にパンくずリストを表示するための機能が提供されます。さらに、パンくずリストの外観や動作を詳細にカスタマイズするオプションも豊富に用意されています。
- カスタマイズの自由度が高く、テーマやプラグインに依存せずに、独自のスタイルでパンくずリストを表示することが可能です。
- 無料版を使用する場合の注意点:
- 無料版では、Google検索結果でのパンくずリスト表示のために必要な構造化データは自動生成されますが、サイト上に視覚的にパンくずリストを表示するための機能は提供されません。
- そのため、テーマに標準搭載されているパンくずリスト機能や、無料のパンくずリスト専用プラグインを利用することを検討するのも良い選択肢です。
結論: AIOSEOを使用すれば、検索結果におけるパンくずリストの表示をサポートするための基本的な機能を無料で利用できます。ただし、サイト上にパンくずリストを実際に表示し、詳細にカスタマイズするには、有料版へのアップグレードや、テーマの機能を利用するかカスタムコードを追加する必要があります。サイトのナビゲーションを強化したい場合は、これらの方法を検討してみましょう。
リンク切れページの修正
サイトの規模が大きくなるほど発生しやすいのがリンク切れ(404エラー)です。リンク切れは、クローラーの回遊を妨げるだけでなく、リンク切れが多発するとユーザーの離脱(サイトを離れてしまうこと)につながり、クローラビリティだけでなく、ユーザビリティの面でもサイトの評価を落とす要因となります。そのため、リンク切れは見つけ次第、迅速に修正することが重要です。
Google Search Consoleを使用してリンク切れ(404エラー)を確認する方法
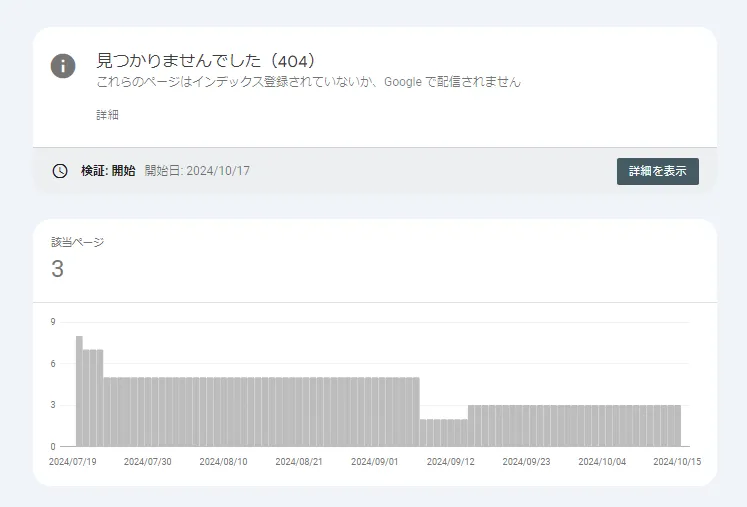
Google Search Consoleを利用すれば、リンク切れページを簡単に確認することができます。具体的な手順は次の通りです:
- Google Search Consoleにログインします。
- 左側のメニューから「インデックス」を選択し、その下にある「ページ」をクリックします。
- 「エラーがあるページ」セクションで、リンク切れのあるページが表示されます。特に「見つかりませんでした(404)」というエラーがあれば、それがリンク切れのページです。
- 具体的なURLのリストを確認したい場合は、「見つかりませんでした(404)」をクリックすると、リンク切れページの詳細なURLリストが表示されます。
- 各URLをクリックして「URL検査」を実行すれば、エラーの原因や、そのページへのリンク元の情報を得ることができます。
また、「カバレッジ」レポートでも詳細なエラー情報を確認可能です。メニューの「インデックス」から「カバレッジ」を選択し、エラーが発生しているページの一覧を確認することができます。
リンク切れを見つけた後の対応策:
- 削除したページの場合:代替のページへ301リダイレクトを設定する。
- URLが変更された場合:新しいURLへ301リダイレクトを設定する。
- 一時的な問題の場合:ページを復旧させる。
- 不要なページの場合:404または410ステータスコードを返して適切に削除する。
定期的にGoogle Search Consoleをチェックして、リンク切れを早期に修正することで、クローラビリティとユーザビリティの向上が図れます。また、サイトの評価が下がることを防ぎ、検索エンジンからの信頼性を保つことにもつながります。
ユーザー体験を意識したクロール最適化

最新のSEOトレンドでは、ユーザー体験(UX)やページ体験(Core Web Vitals)の重要性がますます高まっています。ページの読み込み速度、視覚的な安定性、インタラクティブ性などの要素は、検索エンジンのクローラーにも大きな影響を与えるため、これらを考慮したサイト設計が不可欠です。クローラーが効率的にサイトを巡回できるようにするためにも、これらのページ体験を改善することが重要です。
クローラビリティを向上させるためには、最新のWeb技術やSEO対策を組み合わせることが効果的です。特に、ページ速度の最適化やモバイル対応の強化など、ユーザーの快適な閲覧体験を実現しつつ、クローラーにとっても効率的なサイト運営を行いましょう。
SEOの最新トレンド

現在のSEOは、単なるキーワードやメタタグの最適化だけでなく、ユーザー体験や信頼性を重視した戦略が必要とされています。特に、Googleの品質評価ガイドラインや、AI技術の進化に伴う新しい取り組みが注目されています。以下では、SEOの最新トレンドとして重要な2つの要素について解説します。
E-E-A-T(経験・専門性・権威性・信頼性)の重要性
近年、SEOの世界で注目されているのが「E-E-A-T」(経験・専門性・権威性・信頼性)という概念です。これは、Googleの品質評価ガイドラインに基づき、信頼性のあるコンテンツを評価するための指標となっており、特に専門性の高い業界において重要視されています。E-E-A-Tの基準を満たすためには、信頼できる情報源からの引用や、著者のプロフィールを強化するなどの工夫が求められます。SEO戦略を考える際には、このE-E-A-Tを意識し、質の高いコンテンツを提供することが重要です。
本記事のフッターでも著者情報を掲載しているのは、この理由です。simple author box というプラグインで作成しています。
AIとSEOの関係

近年、生成AI(ジェネレーティブAI)の進化がSEOの世界にも大きな影響を与えています。AI技術を活用したコンテンツ作成や、SEO最適化の自動化が進んでおり、AIを活用した戦略が今後ますます重要になると考えられます。特に、自然言語処理(NLP)技術を活用した検索エンジンの進化により、ユーザーの検索意図に応じた最適なコンテンツ提供が求められます。SEO戦略には、AI技術の理解とその応用が不可欠です。
AIを利用してライティングを進めても決して悪いわけではなく、ユーザーファーストになるWEBコンテンツを最適化できれば検索エンジンからの評価を得ることができます。
このように、SEOの最新トレンドは単なる技術的な施策に留まらず、ユーザーの信頼を得るためのコンテンツ作成や、AIを活用した効率的な最適化がますます求められています。
まとめ
クローラーはインターネットサイトの情報を収集するロボットプログラムで、検索エンジンの表示順位に関わっています。クローラーにチェックしてもらいやすくするためには、クローラビリティが重要です。Googleの無料ツール「Google Search Console」を併用し、クローラーが見やすいサイト構造にする必要があります。
今回は結果的に、All in One SEO 押しの内容になりましたが、WEB担当者が一番簡単に再現性高く実施できる内容より、この度の解説となりました。
このクロール最適化も、1回やって終わりではありません。新しいページや修正があれば、随時リクエストし、内部リンクの充実化、リンク切れのチェックなど、継続的に行うことでサイトの品質を維持していきましょう。

カッティングエッジ株式会社 代表取締役 竹田 四郎
WEBコンサルタント、SEOコンサルタント。WEBサイトの自然検索の最大化を得意とする。実績社数は2,500社を超える。
営業会社で苦労した経験より反響営業のモデルを得意とし、その理論を基に顧客を成功に導く。WEBサイトやキーワードの調査、分析、設計、ディレクションを得意とする。上級ウェブ解析士、提案型ウェブアナリスト、GAIQの資格を保有する。著書:Kindle・POD出版で高まるEEATとサイトSEO戦略 コンテンツマーケティングは設計が9割