

投稿日:2026年6月11日 | 最終更新日:2026年6月11日
AIで助詞をチェックすれば完璧な文章が書けると思われがちです。ただし、実際には「精度が上がったこと」と「どのAIをどう使い分けるか」は別の問題です。この記事では、2026年現在の主要LLMの「てにをは」チェック精度を比較し、誤検出を避ける実務判断と、AI校正に頼り切らない文章設計の考え方を解説します。
「てにをは」とは何か|日本語助詞の役割とSEOへの影響
AI校正ツールの精度を語る前に、「てにをは」という言葉が何を指し、なぜSEOに影響するのかを整理しておく必要があります。助詞は文章の骨格を支える存在であり、1文字の違いが意味を大きく変えるためです。このセクションでは、助詞の役割と、読みやすさが検索評価に与える間接的な影響を押さえたうえで、AI時代に求められる「主張の強さ」との両立について解説します。
「てにをは」が文章の意味を決定づける仕組み
「てにをは」は、日本語の助詞である「て」「に」「を」「は」を総称した 表現です。現代では助詞全般を指す言葉として使われており、主語・目的語・ 場所・時間といった文中の要素同士の関係を示す役割を担っています。
助詞の怖さは「文法ミス」ではなく「意味のすり替え」にあります。たとえば 「担当者に確認した」と「担当者が確認した」では、確認した人物が正反対に なる。前者は書き手側が問い合わせた話、後者は担当者自身が動いた話です。 誤字なら読者は気づいて読み飛ばせますが、助詞のすり替えは「文章として 成立したまま意味だけが間違う」ため、読者は誤解したことにすら気づきません。
実務の現場では、この「成立したまま間違う」が最も厄介です。特にWeb コンテンツは流し読みされることが多く、一文で意味が完結するよう設計 しなければ、読者は誤った理解のままページを離れてしまいます。だからこそ、 どの単語が主語でどの単語が目的語なのかが一読で伝わる助詞の置き方が、 書き手に求められると考えると理解しやすいでしょう。
助詞のミスがSEO評価に与える間接的な影響
助詞のミスがSEOに効く、と聞くと身構えるかもしれませんが、これは半分 正しく、半分は誤解です。助詞の誤用そのものに検索エンジンのペナルティが あるわけではありません。効いているのは、もっと手前の「読者の挙動」です。
具体的には、読みにくさが離脱を生み、離脱が滞在時間や直帰率という数値に 表れる。検索エンジンが直接見ているのは助詞ではなく、この読者の反応の方だ と考えると整理しやすいでしょう。つまり助詞は「順位を決める要因」ではなく、 「読者を逃さないための前提条件」という位置づけになります。
だからこそ、助詞を一語直すごとに順位が動くといった期待は持つべきでは ありません。E-E-A-Tが重視される現在、文章の品質は評価に関わりますが、 助詞はあくまで土台です。土台が崩れていれば内容も伝わらない——その意味で 押さえておくべき要素だと捉えるのが現実的です。
「読みやすさ」と「主張の強さ」の両立がカギになる理由
AI校正ツールを使えば、助詞のミスはほぼ防げるようになりました。ただし、AIを起点に作成する記事は、どうしても人間特有の主張が弱く、内容の「尖り」が欠ける傾向にあります。
昨今、noteがSEOに強いと言われていますが、それはドメインレーティングの高さだけでなく、書き手である著者の主張の強さが一次情報として機能しているからだと考えられます。助詞を適切に使うことで、自社や自身の文章の主張をより分かりやすく表現できるため、ここを間違えずに使い分けていくことが必要です。
AIが普及する以前、Webライターに執筆を依頼していた時期は、ライター自身が助詞を間違えることも多々ありました。その間違い自体も人間味ではありましたが、現在はAIを活用すればほぼミスを防げます。AIで文章を高い精度でまとめ上げつつ、自分自身の主張を組み込むことで、検索エンジンに評価される記事を作っていくべきです。
2026年のAI文章校正|主要LLMの「てにをは」チェック精度
AIによる日本語校正は、2023年頃まで「過剰修正」と「英語的な語順への引きずられ」が実務上の課題でした。ただし、2026年現在、主要LLMの「てにをは」チェック精度は実用レベルに到達しています。モデルごとに得意分野が異なるため、文章の種類や運用環境に応じて使い分けることが現実的です。
この違いを知らずに「AIに任せれば完璧」と考えると、誤検出や文体の崩れに気づかないまま公開してしまうリスクがあります。ここでは、2026年時点での主要LLMの特性を整理し、実務でどう選ぶべきかを示します。
下記は、従来の てにをは の基礎を解説した記事です。
「てにをは」とは?その意味と具体的な使い方について紹介
ChatGPT 5.5|文脈依存のねじれを高精度に検出
2026年4月に登場したGPT-5.5は、主語と述語が数十行離れた長文でも、係り受けを 破綻させずに助詞を整合させる能力が際立っています。「〇〇が重要です。それを 実現するには…」のように指示語と助詞の対応が複雑な文章でも、主語と述語の 関係を正確に追跡できると考えると理解しやすいでしょう。
ただし、これは「完璧」を意味しません。GPT-5.5は指示への追従性が高い反面、 流暢な表現へ自動的に寄せる「流暢性バイアス」が他社モデルより強めに働きます。 文法的に正しい箇所まで読みやすさを理由に書き換えてしまうため、著者の語り口を 残したいオウンドメディアやnote記事には向きません。むしろ「修正前後を比較表に し、修正理由を言語学的に添える」といった複雑な校正タスクでこそ力を発揮します。
実務では、初稿段階の構造的なミス(主語の欠落・係り受けの破綻)を洗い出す 用途に使い、文体を残したい推敲段階では別のモデルへ切り替える運用が現実的です。
Gemini 3.1 Pro / 3.5 Flash|音声文字起こし補正と大量一括処理向け
2026年2月発表のGemini 3.1 Proと軽量版3.5 Flashは、崩れた口語の補正に定評が あります。話者の「えー」「あのー」といったフィラーを除去しながら、口語で 脱落しがちな助詞を文脈から補完する精度が高く、「〇〇について、それについて 説明します」のような重複表現も自然に整理できます。
特に軽量版の3.5 Flashは超長文を低レイテンシ(入力から応答までの待ち時間が 短いこと)で処理できるため、数十本単位の記事を一気にスキャンする用途に 向いています。インタビューや対談記事の編集 工程を短縮したい現場では、まずGeminiに通すという運用が現実的でしょう。
ただし、超長文を一括処理する際、文章の中盤で注意力が低下する「Lost in the Middle」が起き、細かい助詞の誤用を見落とすことがあります。1回目で文法、 2回目で表現と段階的に分けて通すと取りこぼしを抑えられます。なお、旧世代で 課題だった「日本語出力への他言語混入」は、最新版では混入率0.03%未満まで 改善されている点も実務上は安心材料です。
Claude Sonnet 4.6 / Opus 4.8|誤検出が少なく文体を保つ保守的校正
Claude Sonnet 4.6と最上位のOpus 4.8は、誤検出(誤っていない箇所を誤りと判断 するエラー)が全モデルの中で最も少ないという特性を持ちます。他のモデルが 「修正すべき」と判断する箇所でも、文脈的に許容されると見れば過剰な書き換えを 避けるため、元の文体を保ったまま助詞のミスだけを拾えると考えると分かりやすい でしょう。
実際に、カッティングエッジでの記事制作でも、著者の語り口を崩さずに助詞だけを 直す用途で活用しています。特に既存記事のリライトでは、元の文体を維持したまま 精度を上げる必要があるため、この保守的な姿勢が実務に合います。近年は ガードレール設定との統合が進み、「コードブロックや固有名詞は変更しない」と いった指示への準拠率がほぼ100%に達した点も、安心して任せられる理由です。
一方で、慎重に検証するアーキテクチャゆえ、大量の文書を秒単位で一括処理する スピード最優先のタスクでは、Gemini 3.5 Flashなどに速度面で劣る場合があります。 文体を守りたい仕上げはClaude、速度がほしい一括処理はGeminiと、用途で 使い分けるのが現実的です。
Llama-3-ELYZA-JP-70B|ローカル環境での純粋な文法校正
Llama-3-ELYZA-JP-70Bは、ローカル環境で動作する日本語特化モデルであり、外部 APIに文章を送らずに校正できる点で、機密性の高い文書に適しています。金融・ 医療・法律など、社外のクラウドに原稿を出せない領域での文法校正が主な活躍の場 です。
注目すべきは精度の伸びです。かつて国産モデルは文章生成はできても文法誤り訂正 という専門タスクは苦手でしたが、大規模化と高品質な日本語コーパスでの学習に より、現在はグローバル最上位モデルの標準版に匹敵する適合率に達しています。 助詞の選択や動詞の活用といった日本語固有の規則では、多言語モデルを上回る スコアを記録する場面もあります。
ただし、これは70B以上の大規模モデルに限った話です。パラメータの小さい軽量 モデルでは、意味の近い別の単語へ勝手に置き換える「流暢性バイアス」が暴走 しやすく、正確な訂正が難しくなります。導入する際は70B以上を選び、最終 チェックは人間か別モデルと併用するのが現実的だと考えておくとよいでしょう。

AIでは防げない「てにをは」の誤検出リスクと回避策
AI文章校正の精度が向上したとはいえ、完璧ではありません。実務の現場では「AIが正しいと判断した助詞が、実際には文脈に合っていない」というケースが依然として発生します。このセクションでは、2026年現在のAI校正でも防ぎきれない誤検出のパターンと、それを回避するための実務的な対策を解説します。
同音異義語・ハルシネーション・Lost in the Middle問題
AIによる「てにをは」チェックで最も厄介なのが、同音異義語の誤変換です。「私は彼に会った」と「私は彼に遭った」では助詞は同じでも意味が異なります。AIは文脈を読み取る能力が向上しましたが、専門用語や固有名詞が絡む場合、誤った漢字を選択することがあります。
ハルシネーション(AI特有の誤生成)も無視できない問題です。存在しない文法ルールを「正しい」と判断し、本来適切だった助詞を不適切な形に修正してしまうケースが報告されています。特に長文を一度に処理する場合、文章の中盤部分で文脈の把握精度が低下する「Lost in the Middle問題」が顕在化します。
これらの問題に対処するには、AIの出力を盲信せず、最終的に人間の目で確認することが不可欠です。特に専門性の高い文章や、著者の主張が強く反映された文章では、AIが「標準的な日本語」に寄せすぎて、意図した文脈を損なう可能性があります。
過剰修正とイングリッシュ・フィルターはどう解消されたか
2023〜2024年のAI文章校正では、過剰修正が大きな課題でした。文法的には正しくても、文体や語感を損なう修正が頻発し、「AIに校正させると文章が無個性になる」という批判が多く見られました。イングリッシュ・フィルター(英語由来の文法規則を日本語に適用してしまう傾向)も、不自然な助詞の配置を生む原因となっていました。
これらの問題は、GECアンサンブル(編集多数決)技術の導入により大幅に改善されました。複数のAIモデルが同じ文章を校正し、最も自然な修正案を多数決で選択する仕組みです。一つのモデルに依存しないことで、極端な修正や誤検出を抑制できます。
ただし、この技術を活用するには複数のAIモデルを並行して利用する環境が必要です。実務では、メインで使用するAIモデルを決めつつ、違和感のある箇所だけ別のモデルで再確認する運用が現実的といえます。
ルールベース事前スキャン+LLM校正のハイブリッド型が現実的

AIに全てを委ねるのではなく、ルールベースのツールとLLM(大規模言語モデル)を組み合わせる「ハイブリッド型」が、現在最も安定した運用方法です。ルールベースツールは「助詞の重複」「主語述語のねじれ」など、明確なパターンを高速で検出できます。一方、LLMは文脈依存の微妙なニュアンスを判断する能力に優れています。
実務では、以下の順序で校正を進めると効率的です。
- ルールベースツールで形式的なエラーを一括検出
- LLMで文脈を考慮した助詞の適切性をチェック
- 最終的に人間が音読して違和感を確認
この3段階のプロセスを踏むことで、AIの誤検出を最小限に抑えつつ、効率的に文章品質を高められます。特に大量の記事を扱う場合、最初の段階で機械的なミスを削減しておくことで、後続の校正作業の負荷が大幅に軽減されます。
AI校正に頼り切らない文章設計|主張の強さを残す実務判断

AIの校正精度が上がったことで、助詞のミスは確実に減りました。一方で、AIを起点にした記事は「正確だが主張が弱い」という課題を抱えやすくなっています。この問題は、SEOの実務現場でも見過ごせない影響を持ちます。検索エンジンが評価するのは「読みやすさ」だけでなく、E-E-A-Tの「Experience(経験)」や「一次情報としての著者の視点」だからです。
AIを起点にした記事が「尖り」を欠ける理由
AIは大量のデータから平均的な表現を生成します。そのため、出力される文章は「誰もが納得する内容」にはなりやすいものの、「この著者だから言えること」という固有性を持ちにくい構造になっています。助詞が正しくても、主語が曖昧で「誰が判断したのか」が見えない文章は、読者の記憶に残りません。
実務の現場では、AIが生成した初稿をそのまま公開するケースが増えています。ただし、そうした記事は競合との差別化が難しく、検索上位を維持できない傾向があります。「AIで精度を上げつつ、著者の判断軸を後から組み込む」という二段階の設計が現実的です。
丁度思い出したのですが、地元の中華料理屋の料理長と仲が良いです。彼はよく「俺の味がわかるお客さんに食べてほしい。中華料理なんてどこも同じだと思うかもしれないが、実はそんなことはない。わかる人間が食べれば俺の味がわかる。だから私は一生懸命作っている。俺の味がわかる人に食べてほしいのだ」と言っていました。
これをコンテンツ制作に例えると、苦労して書いた記事は、まさに「自分の味」や「我が社の秘伝のタレ」のようなものが含まれるべきではないでしょうか。つまり、自社の秘伝のタレに相当するものがないコンテンツは、少し寂しいものではないでしょうか?あなた、御社のコンテンツには「俺の味」がありますか?
noteがSEOに強い本質|一次情報としての著者の主張
noteが検索結果で上位に表示されやすい理由は、ドメインレーティングの高さだけではありません。note上で公開される記事の多くは、著者自身の実体験や主観的な判断を前面に出しています。この「著者が実際に試した・感じた・判断した」という一次情報が、検索エンジンにとって評価すべき要素として機能しています。
助詞が多少不自然でも、「私はこう考える」「実務でこういう失敗をした」という主語が明確な文章は、読者の行動変容を引き出しやすくなります。AIで書いた文章に、後から「私は〜と判断しました」「現場では〜というケースをよく見ます」という一人称の視点を追加するだけで、記事の強度は大きく変わります。
AIで精度を上げつつ自分の判断軸を組み込む方法
AIを使った文章作成の実務フローは、以下の手順で組み立てると主張と精度を両立できます。
- 初稿生成:AIに構成案と概要を渡し、助詞を含めた文法的に正確な初稿を作らせる
- 主張の挿入:著者自身の実体験・判断・失敗例を1〜2箇所に追加する
- 再校正:追加した部分の助詞をAIで再チェックし、文体の統一を図る
このフローでは、AIが「正確さ」を担保し、人間が「固有性」を注入する役割分担が成立します。実務では、初稿を書く時間を大幅に短縮しつつ、最終的な品質を著者がコントロールできる形が理想です。AIに全てを任せるのではなく、「AIで土台を作り、人間が仕上げる」という判断が現実的でしょう。
実務で使える「てにをは」チェックの運用フロー
AIの精度が上がったとはいえ、実務で記事を量産する現場では「どのタイミングでどのAIを使うか」という運用設計が必要です。初稿作成時と推敲時で求める精度が異なり、使うべきツールも変わってきます。ここでは、実際に運用できるレベルまで落とし込んだ「てにをは」チェックのフローを3つの観点から整理します。
初稿作成時と推敲時で使うAIを切り替える
初稿作成時には、文章の流れを止めずに書ききることが優先されます。この段階でAIに細かく校正させると、リズムが崩れて執筆が進まなくなるリスクがあります。まずは自分の言葉で書き切り、推敲段階でAIに助詞の精度チェックを任せる方が現実的です。
推敲時には、誤検出が少なく文体を保つ保守的なモデルを使うと、元の語り口を 崩さずに助詞のミスだけを拾えます。係り受けの複雑なねじれに強いモデルは 有効な一方、流暢な表現へ自動的に書き換えてくることがあるため、確定稿の直前に 使う方が安全だと考えると判断しやすいでしょう。
初稿では速度重視、推敲では精度重視という使い分けを意識すると、AIに振り回されずに作業を進められます。
音読による確認とAI校正を組み合わせる実務手順
音読を勧める記事は多いのですが、「なぜ効くのか」まで踏み込んでいるものは 意外と少ないです。音読が助詞のミスを拾えるのは、目で追う黙読が「意味」を処理 するのに対し、声に出す音読は「リズム」を処理するからです。助詞のねじれは 意味より先にリズムの乱れとして表れるため、黙読では素通りした箇所で舌が つっかえる。この「つっかえ」こそが検出装置になります。
そこで実務では、AIの「意味のチェック」と音読の「リズムのチェック」を 別レイヤーとして組み合わせると、取りこぼしが減ります。
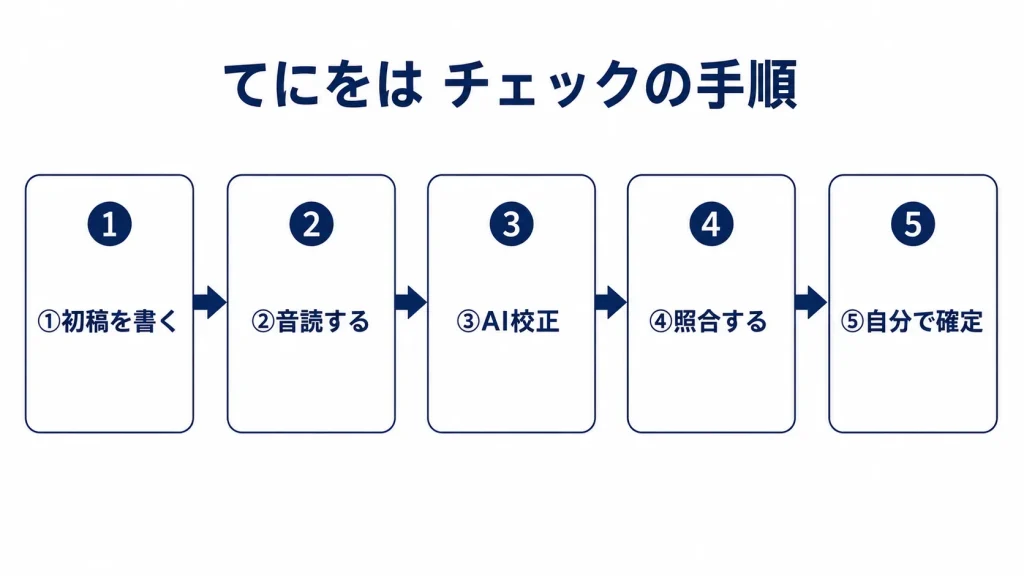
- 初稿を書き上げる(助詞は気にせず書く)
- 自分で音読し、リズムが崩れる箇所をメモする
- AI校正ツールで助詞の誤りを検出する
- 音読で気になった箇所とAIの指摘箇所を照合する
- 最終的に自分の判断で修正を確定させる
この流れで進めれば、AIの誤検出に引きずられることなく、読者にとって自然な 文章に仕上げられます。AIとの照合まで含めて数分の作業ですが、機械の判断と 身体感覚という性質の違う2つの目を通せる点に意味があると考えると、組み込む 価値が見えてくるでしょう。
Webライター時代と比較したAI活用のコストパフォーマンス
AI普及以前、外部のWebライターに執筆を外注していた時期は、助詞のミスが頻発していました。ライターのスキルに依存するため、校正担当者が後工程で手直しする必要があり、時間とコストがかかっていたのが実態です。
現在は、ライターが初稿を書いた後にAI校正を通すことで、助詞の精度を事前に底上げできます。校正担当者の負荷が減り、全体の制作スピードが上がる効果も確認されています。ただし、AIで修正した箇所が文脈上おかしくなるケースもあるため、最終確認は必ず人間が行うべきです。
AI活用によってコストは下がりましたが、品質管理の責任は人間側に残っています。「AIに任せれば完璧」という思い込みを捨て、自分の判断軸を持つことが、現場では最も重要です。
よくある質問(FAQ)
Q1. AIで「てにをは」を100%完璧にチェックできますか?
現時点では100%完璧ではありません。同音異義語の誤変換や、文脈依存の助詞判断でミスが発生することがあります。AI校正と音読による人間の確認を組み合わせることで、実務上問題ないレベルの精度を保てます。
Q2. どのAIモデルが日本語の助詞チェックに最も適していますか?
唯一の正解はなく、目的による使い分けが現実的です。指示への追従や明確な リライトを求めるならGPT系、音声文字起こしの補正や大量処理ならGemini系、 文体を崩さない保守的な校正ならClaude系、機密文書のローカル処理なら日本語 特化モデルが向きます。モデルは更新が速いため、最新版で比較するのが確実です。
Q3. AIに校正を任せると文章の個性が失われませんか?
AIを起点にすると主張が弱くなる傾向があります。初稿は人間が書き、推敲段階でAIを使う流れにすることで、文章の尖りを残しつつ助詞の精度を上げることができます。AIは補助ツールとして位置づけましょう。
Q4. 音声入力で書いた文章のてにをははAIで直せますか?
Gemini 3.1 ProやGemini 3.5 Flashは音声文字起こし後の助詞補正に強みがあります。 フィラー除去と助詞の自動補完を同時にこなせる点が実務で重宝されています。 ただし、話し言葉特有のねじれは完全には直せないため、音声入力後は必ず 人間が文脈を確認する工程を挟むことが現実的です。
Q5. 無料で使える日本語文法校正AIはありますか?
ChatGPT(無料版)やClaude(無料枠)で基本的な助詞チェックは可能です。ただし、長文処理や高精度な校正には有料プランが必要になるケースが多いため、用途と予算に応じて判断してください。
まとめ
2026年現在、主要LLMの日本語「てにをは」チェック精度は実用レベルに達しています。GPT・Gemini・Claude・Llamaはそれぞれ得意領域が異なり、文脈依存の助詞ねじれ検出、音声文字起こし補正、誤検出を抑えた保守的校正、ローカル環境での純粋な文法チェックといった特性を持ちます。ただし同音異義語やハルシネーション、長文のLost in the Middle問題は残存しており、ルールベース事前スキャンとLLM校正を組み合わせたハイブリッド型が現実的です。
AIを活用する際に注意すべきは、精度を上げることと引き換えに文章の「尖り」を失うリスクです。noteがSEOに強いのはドメインレーティングだけでなく、著者の主張が一次情報として機能しているからです。助詞を正確に使うことで自分の判断軸をより明確に表現できるため、AIで校正精度を担保しつつ、自身の実務感・主張を組み込む設計が求められます。
まずこれだけ覚えておきましょう。AIは助詞の精度を上げる道具であり、文章の方向性を決めるのは書き手自身です。校正をAIに任せ、判断と主張は自分で持つ。この役割分担が、検索エンジンにも読者にも評価される記事を生み出す現実的な実装方法です。
出典
本記事で参照した公的機関・一次情報は以下のとおりです。
1. Nelson F. Liu et al. Lost in the Middle: How Language Models Use Long Contexts(Transactions of the ACL, 2024)
2. 株式会社ELYZA ELYZA、Llama 3.1ベースの日本語モデル「Llama-3.1-ELYZA-JP-70B」を開発

カッティングエッジ株式会社 代表取締役 竹田 四郎
WEBコンサルタント、SEOコンサルタント。WEBサイトの自然検索の最大化を得意とする。実績社数は2,500社を超える。
営業会社で苦労した経験より反響営業のモデルを得意とし、その理論を基に顧客を成功に導く。WEBサイトやキーワードの調査、分析、設計、ディレクションを得意とする。上級ウェブ解析士、提案型ウェブアナリスト、GAIQの資格を保有する。著書:Kindle・POD出版で高まるEEATとサイトSEO戦略 コンテンツマーケティングは設計が9割














